HA/DR for Developers: Building Resilient Systems Without Losing Sleep
TL;DR: Your system will fail. But that doesn’t mean your weekend plans have to.
The Day I Missed Knott’s Berry Farm
A few years ago, I had planned a family trip to Knott’s Berry Farm with my wife and daughter. It wasn’t about the destination—it was about finally taking a day off together after weeks of coordinating calendars. But at the time, I was leading platform engineering for a financial services client that was going through a rough stretch: seven production outages in ten days. None were caused by the platform, but every one of them required platform involvement to troubleshoot.
The morning of the trip, nothing happened. No outage. No red alert. But I was so rattled by the prior ten days, so worn down by the sense of looming failure, that I told my wife I couldn’t risk being away. I stayed home. They went without me. And nothing happened. That kind of fear-based decision is exactly what good HA/DR should help prevent. When your systems are designed to tolerate failure, you can tolerate being offline for a day—and maybe even enjoy the ride.

DevOps Without the 2AM Alert
DevOps culture encourages ownership—but too often, that ownership comes at the cost of personal time. You promise your family a day at the amusement park, only to stay home “just in case.” You wrap up work, but can’t stop checking Slack. Burnout isn’t just a risk—it’s baked in.
It doesn’t have to be. Imagine a world where your systems are resilient enough that you don’t have to be. You finish early enough to catch the sunset. You take a day off without stress. You join your family, fully present—not glued to dashboards or deployments. That’s not a fantasy. That’s what good HA/DR design enables.
High Availability (HA) and Disaster Recovery (DR) aren’t just infrastructure concerns or executive metrics—they’re your best tools for building peace of mind. When implemented well, they let you ship with confidence, bounce back from failure, and stop living like you’re always on call.
This post breaks down the key patterns and trade-offs of HA/DR in cloud-native environments—especially in Azure—so you can design for resilience without sabotaging your life.
📖 HA/DR Foundations: Resilience in Two Acts
When your system goes down, you need to recover. That’s Disaster Recovery (DR)—the plan for getting back to production after a disruption. But wouldn’t it be better if you didn’t go down in the first place?
That’s where High Availability (HA) comes in. HA is about designing your system so it rarely goes down. You build in redundancy, isolate failures, and keep critical services running—even when individual components falter.
In simple terms:
- HA minimizes disruption.
- DR minimizes downtime after disruption.
You need both. Together, they form the backbone of resilient systems—systems that bend instead of break.
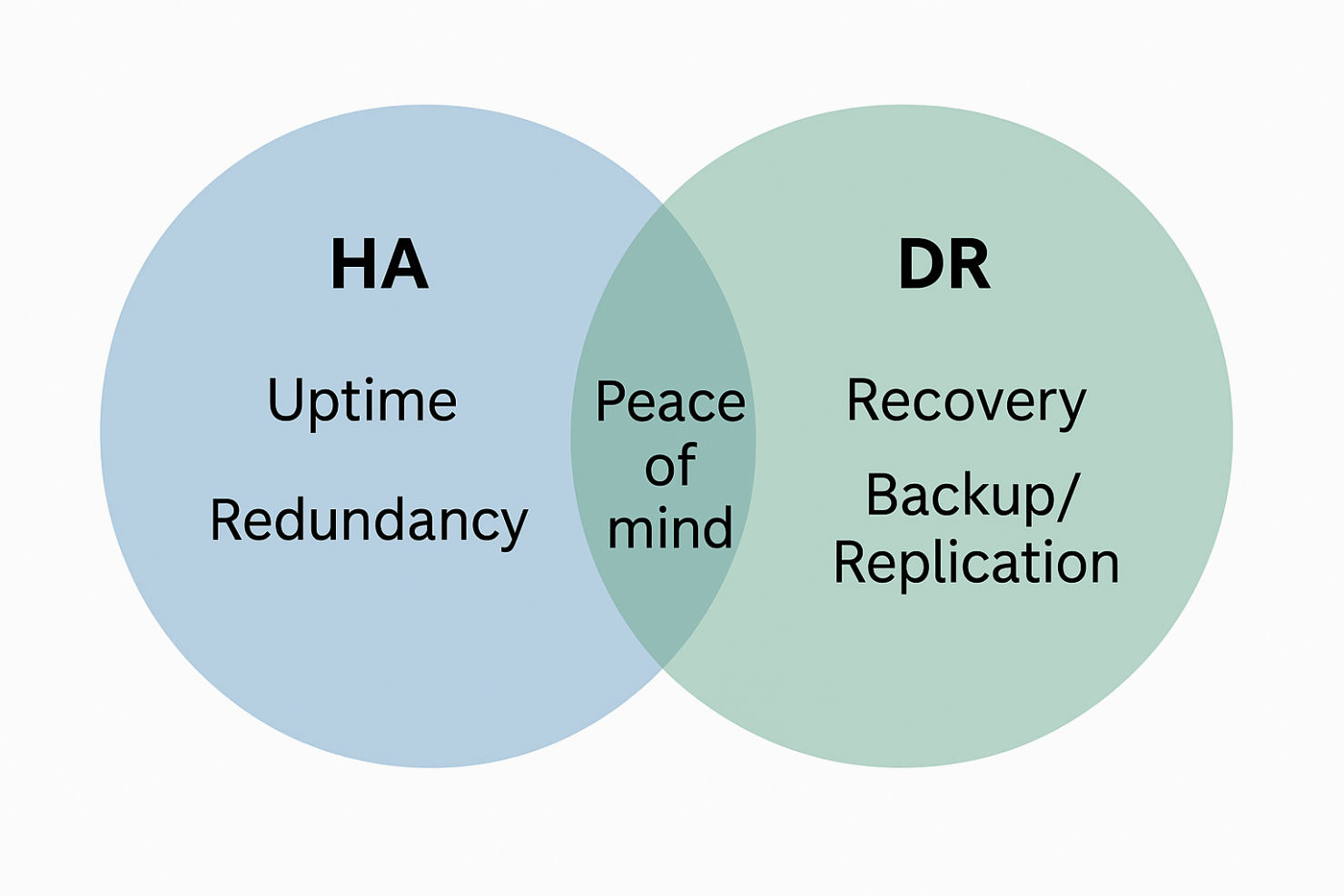
💡 Think of HA as real-time protection and DR as your safety net. The stronger each is, the more confidently you can move.
🧱 High Availability Principles
High availability is the best disaster recovery—because the best outage is the one that never happens.
But designing for uptime doesn’t mean aiming for perfection. It means building systems that degrade gracefully instead of collapsing completely. It’s about buying time, limiting damage, and giving your team room to fix things without waking you up at 2 AM.
Here are the core principles:
- Architect for continuity. Your system should be built so that it rarely goes down in the first place.
- Use bulkheads. Isolate failure domains. If one component breaks, it shouldn’t take the whole platform down with it.
- Assume failure. Every part of your system will fail eventually. Make recovery fast, repeatable, and testable.
- Degrade instead of fail. A partially working system is far better than a total outage.
- Buy time. If you can contain the blast and keep core functionality up, you’ll have the space to find and fix root causes without panic.
💡 High availability isn’t just about uptime. It’s about maintaining control when things go wrong.
🔁 Disaster Recovery Principles
If high availability is about staying up, disaster recovery is about getting back up—fast and safely—after things go wrong.
Disaster recovery (DR) is your safety net. It’s what kicks in when availability fails, when the unexpected hits, or when you need to recover from corruption, deletion, or full-region outages. A good DR plan is the difference between a brief interruption and a resume-generating incident.
Two key metrics define how you recover:
-
RTO (Recovery Time Objective): How quickly must the system be restored? Example: “We must be back online within 30 minutes.”
-
RPO (Recovery Point Objective): How much data can we afford to lose? Example: “We can only lose up to 5 minutes of data.”
You don’t get to pick these numbers in isolation—they come from business needs. But your architecture determines whether you can meet them.
Core DR principles:
- Define realistic RTO and RPO targets. Don’t guess—partner with stakeholders to understand expectations and constraints.
- Automate recovery as much as possible. Manual steps add time and introduce errors under pressure.
- Test your DR plan regularly. If you haven’t run a recovery drill, you don’t have a recovery plan—you have a document.
- Keep dependencies in mind. Recovery isn’t just about data—it’s about DNS, identity, networking, and service interconnects.
- Document and communicate. Everyone should know what to do—and what not to do—when disaster strikes.
💡 Disaster recovery isn’t about avoiding failure—it’s about owning it, containing it, and recovering with confidence.
🔁 Disaster Recovery Patterns: How Hot is Hot?
You’ve got the principles—now let’s talk about what they actually look like in the real world.
In Azure (and most cloud environments), HA/DR strategies aren’t just theoretical—they show up in concrete architectures. Whether you’re dealing with a global SaaS app or an internal line-of-business tool, the patterns you choose will shape your system’s resilience, cost, and complexity.
Let’s break down the most common options, and I’ll tell you which one I like best.
These are disaster recovery strategies—not high availability patterns—and that distinction matters. HA keeps your system running through localized failures. DR brings it back after major disruptions—like full-region outages or data corruption.
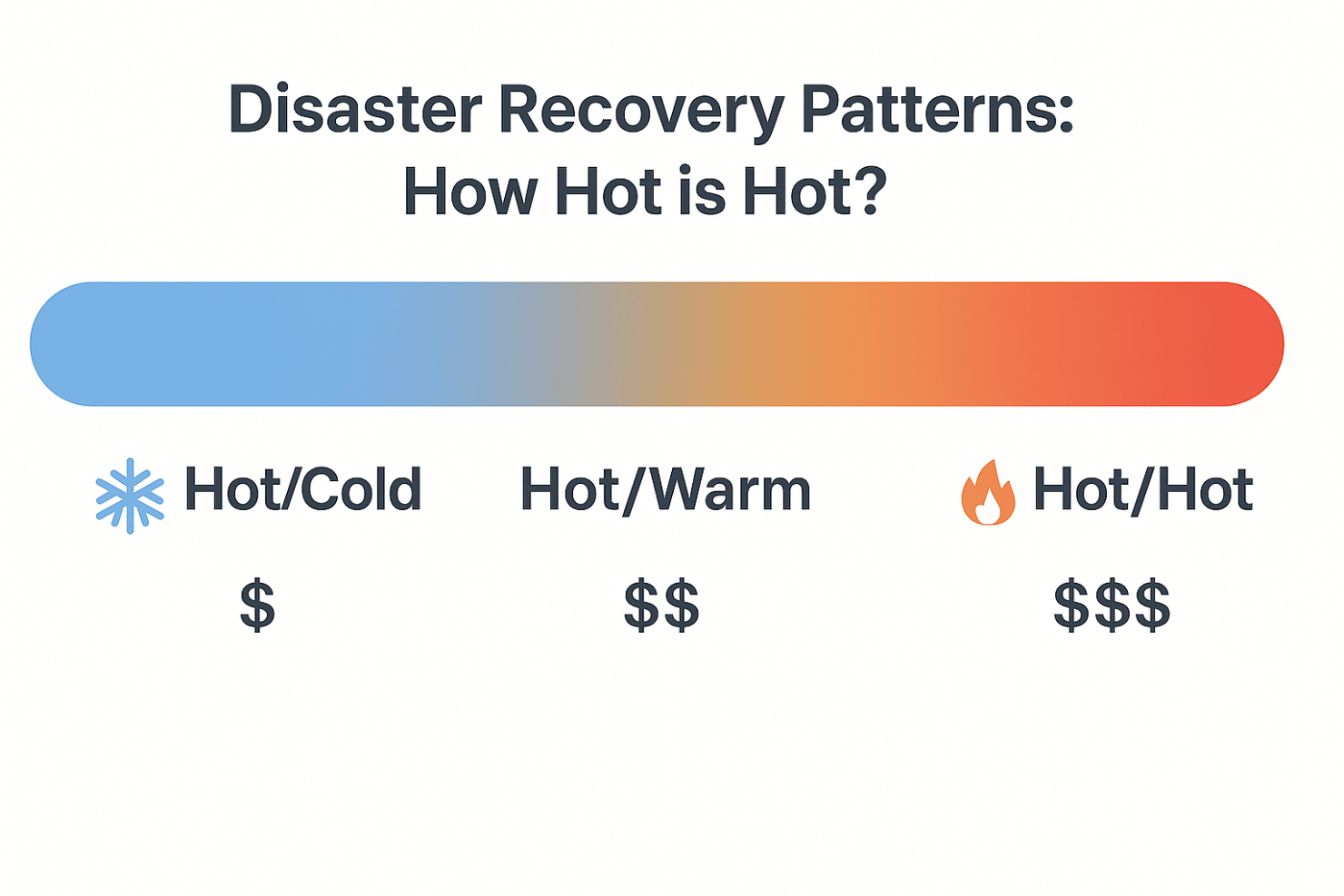
In Azure (and even on-premise), most DR strategies fall into one of three categories, based on how “hot” your standby environment is:
🔥 Hot/Hot
- What it is: Both regions actively serve production traffic.
- Recovery: Instant. Traffic reroutes automatically with little or no downtime.
- Trade-offs: Highest cost, requires real-time data replication, and careful design to avoid conflicts.
- When to use: You have strict RTO/RPO requirements or can’t afford any downtime.
✅ Best resilience, but you’re paying for it every minute.
🔥❄️ Hot/Warm
- What it is: One region handles production. A second is pre-provisioned, idle, and synced—but not serving traffic.
- Recovery: Minutes. Failover typically involves updating DNS or a traffic manager profile—and possibly starting services that were paused to save cost.
- Trade-offs: Lower cost than hot/hot, but still requires maintenance and validation of the passive region.
- When to use: You want a balance of performance, resilience, and cost.
⚖️ The sweet spot for many enterprise workloads.
❄️❄️ Hot/Cold
- What it is: Only the primary region is provisioned. The secondary environment is defined but not deployed.
- Recovery: Hours or more. Failover involves standing up infrastructure and restoring from backup.
- Trade-offs: Cheapest option, but highest risk and slowest recovery.
- When to use: You have generous RTOs or DR is only required for compliance purposes.
🧊 Better than nothing—but know what you’re signing up for.
🧭 High Availability Topologies: Staying Online by Design
Not every failure is a disaster. Most of the time, staying available is about surviving smaller disruptions—like a node crash, a zone outage, or a spike in demand. That’s where high availability (HA) patterns come in.
Many Azure services include built-in HA by default:
- App Service Plans can span multiple Availability Zones with three or more instances.
- Storage Accounts offer Locally Redundant Storage (LRS) and Zone-Redundant Storage (ZRS) to keep your data safe even when a rack or zone fails.
But when your architecture must remain available across a wider blast radius—or serve traffic across geographies—you’re designing for HA at scale. Below are the core patterns:
🔄 Active/Active
- What it is: Two or more regions serve live traffic simultaneously.
- Benefits: Resilient, scalable, and efficient—traffic routing can be uneven; even 5–10% in a secondary region helps validate readiness.
- Prerequisite: Requires Hot/Hot disaster recovery setup underneath.
- When to use: You want maximum availability and live validation of multi-region readiness.
🚀 Every region earns its keep. This is resilience in action.
💤 Active/Passive
- What it is: One region handles all traffic while another remains on standby.
- Benefits: Simpler to operate, lower cost than active/active. Can still meet strict SLAs if DR failover is well-tested.
- Watch out: Passive regions can silently drift out of date. DR drills are essential.
- When to use: You need regional redundancy but can tolerate brief failover time.
🛑 Don’t sleep on your passive region—test it or regret it.
| Topology | Description | Recovery Time | Cost |
|---|---|---|---|
| Active/Active | Traffic split across regions | Seconds | $$$ |
| Active/Passive (Warm) | Standby is provisioned and synced | Minutes | $$ |
| Active/Passive (Cold) | Standby is defined but not deployed | Hours+ | $ |
🔗 HA/DR Combinations: Which Combo Solves the Most Pain?
When you combine High Availability topologies with Disaster Recovery strategies, you get real-world deployment patterns. These combinations are where resilience, cost, and complexity converge.
✅ Active/Active with Hot/Hot
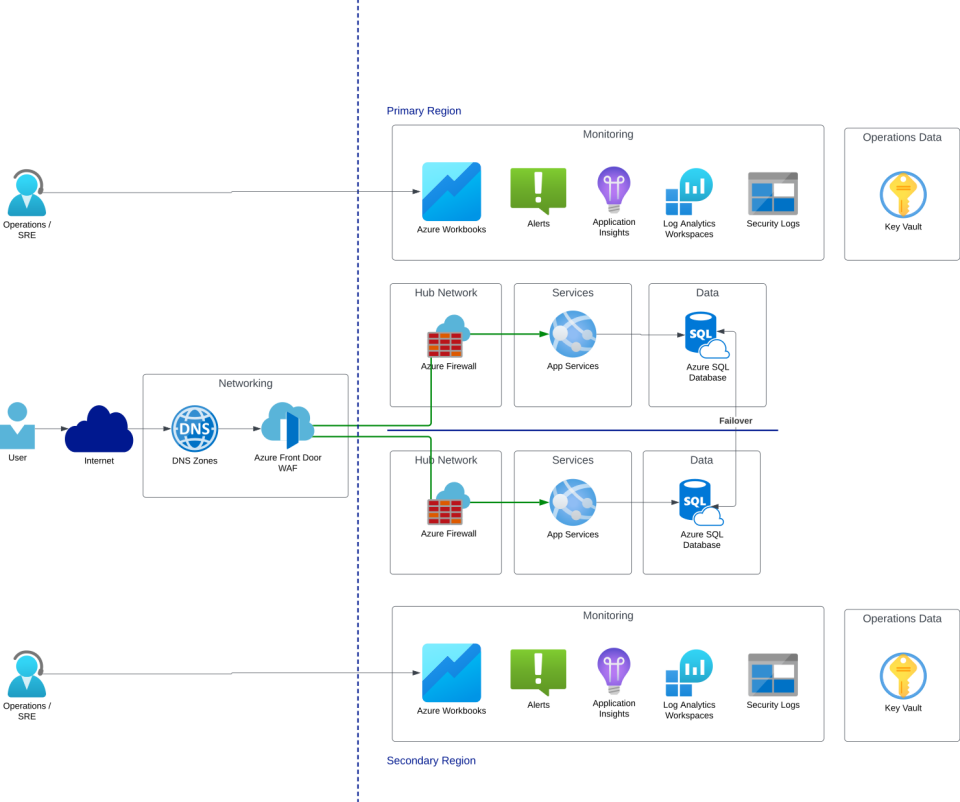
- Active regions are “hot” by definition—each one processes production traffic daily.
- This is the gold standard for resilience: real traffic provides real validation.
- Recovery is fast because traffic can be shifted instantly using Azure Front Door, DNS, or regional load balancers.
- You can optimize cost by unevenly distributing load or scaling regions independently.
💡 No surprise failovers. Every region proves it works—every day.
💤 Active/Passive Combinations
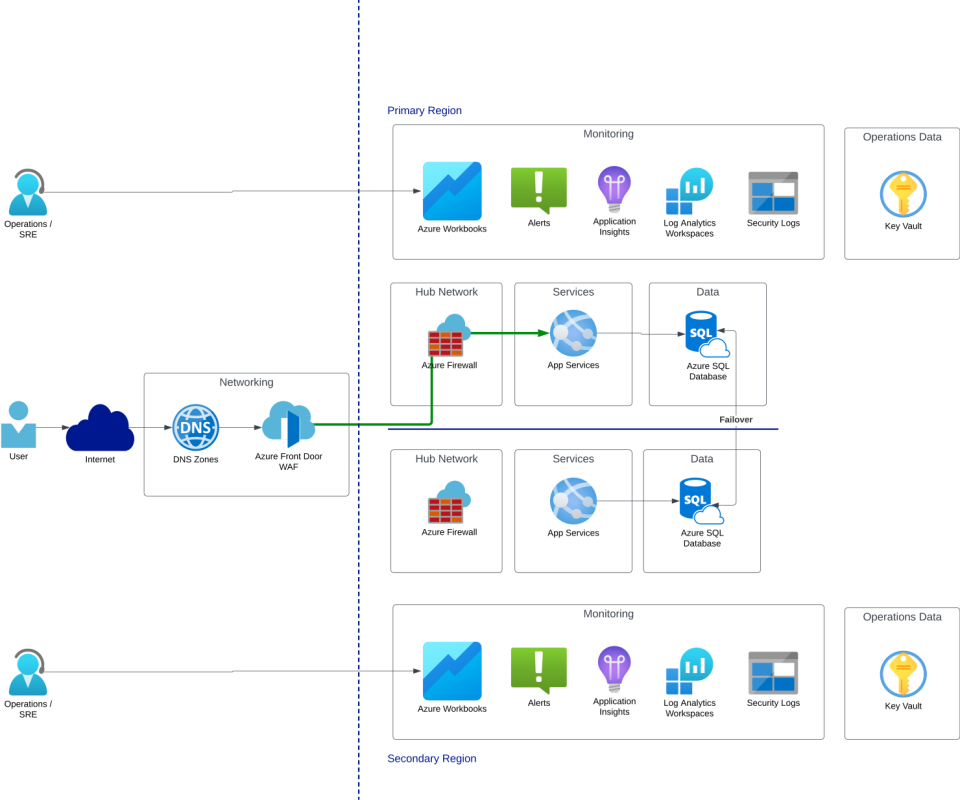
- With Hot/Hot: Technically possible, but often cost inefficient—you’re running two fully loaded regions, but only one serves users. You might use this if your architecture is stateful and can’t yet support true Active/Active, but setting affinity at your global load balancer may be a better long-term solution. Fast failover, simple recovery, but high cost.
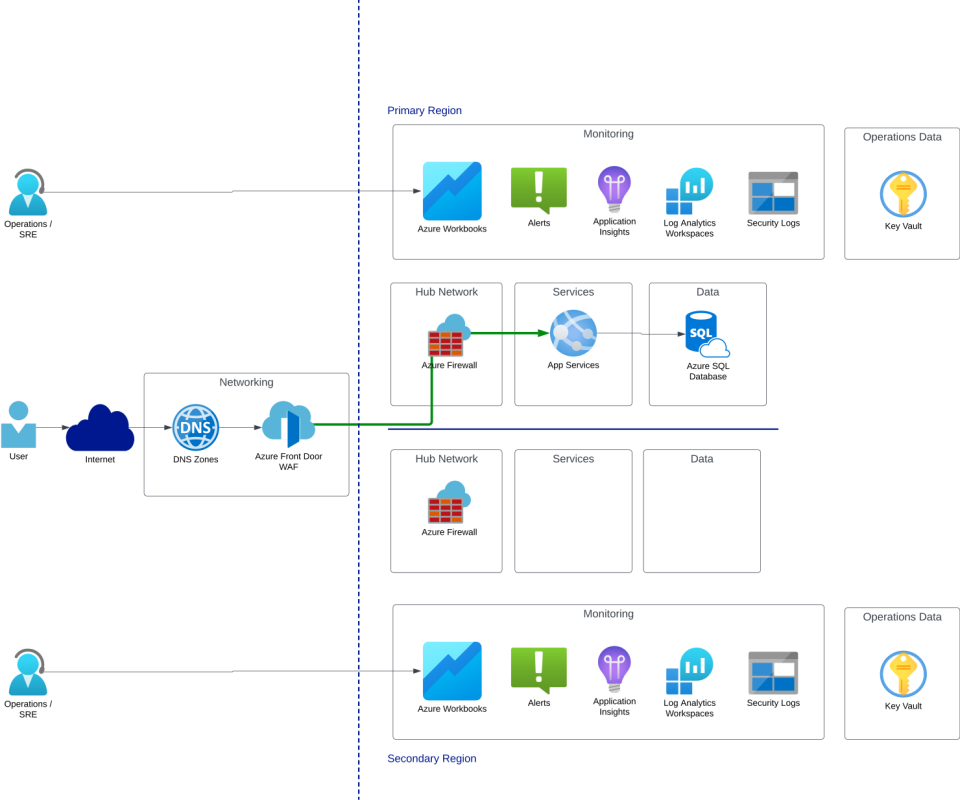
- With Hot/Warm: A cost compromise—less expensive than Hot/Hot, but slower failover and more recovery complexity. Requires testing. Works for most teams.
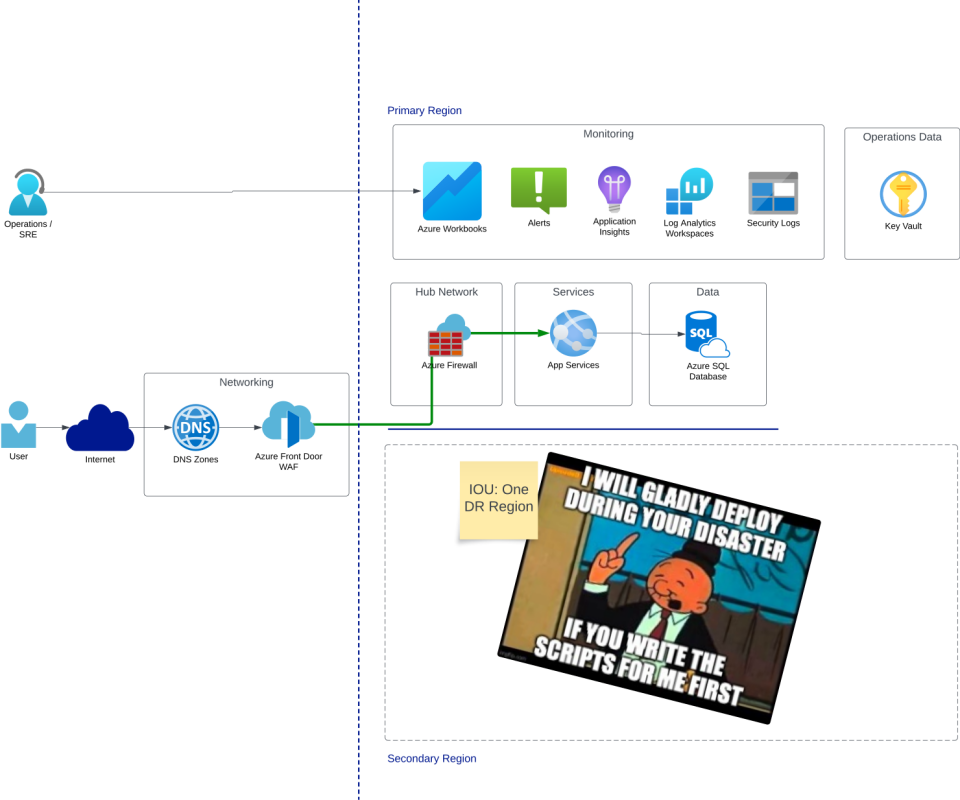
- With Hot/Cold: The cheapest option, but the slowest to recover—and the most likely to surprise you. Requires thorough testing. High risk if neglected.
🏆 My Recommendation: Active/Active with Hot/Hot
HA/DR Combinations
| Active/Active | Active/Passive | |
|---|---|---|
| Hot/Hot | 👑 Best resilience Live validation daily |
😑 Wasted capacity Simple failover 💰 High cost |
| Hot/Warm | N/A | 👍 Good enough Slower failover 🔁 Requires drills |
| Hot/Cold | N/A | 💰 Cheapest Manual recovery 😩 Risky if neglected |
Of all the combinations, Active/Active with Hot/Hot provides the highest level of resilience—and the most peace of mind.
When both regions handle live traffic (even unevenly), you’re constantly validating that failover works. There’s no guesswork, no drift, and no emergency scramble. You get elastic scale, fast recovery, and the confidence to take a day off without watching the dashboard.
✨ It’s not just the most resilient option—it’s the one that lets you sleep at night.
Yes, I understand this recommendation is a bit selfish—I’m optimizing for personal peace of mind alongside the greatest expense. Business needs may override that. But to quote Ferris Bueller:
“It is so choice. If you have the means, I highly recommend [Active/Active with Hot/Hot].”
❗ Objections: Why Not Be Hot?
Let’s face it—when you recommend Active/Active with Hot/Hot, you’re bound to get pushback. It sounds expensive, complicated, and like something only big tech companies can afford. But most of those objections don’t hold up under scrutiny.
And really… why not be hot?

💸 Objection: “Active/Active with Hot/Hot is too expensive!”
Sure, on paper it looks pricey—two regions, duplicated resources, twice the infrastructure. But here’s the thing:
- In the cloud, you’re not paying for hardware—you’re paying for capacity.
- Each region should be scaled to handle normal load—not peak in both places.
- Shared resources (like firewalls) are duplicated in every strategy except Hot/Cold.
- In Active/Active, both regions earn their keep by processing production traffic.
💡 It’s not waste if it’s working.
🧠 Objection: “It’s too complex!”
Managing two live regions sounds hard—until you realize much of the heavy lifting is already done for you:
- Many Azure services offer built-in geo-replication and zone redundancy.
- Infrastructure as code (IaC) makes multi-region deployment repeatable and testable.
- Automation, templates, and observability tooling eliminate most of the risk.
Plus, the payoff isn’t just uptime—it’s peace of mind. That’s worth more than you think.
🧰 You pay Azure to simplify this complexity. Let it.
🔧 Objection: “We’d have to change the app!”
Possibly. But let’s be real: if your app can’t handle another region, it probably isn’t handling this one very well either.
- Your move to the cloud was supposed to improve elasticity and reduce CapEx.
- Any app built for scalability should adapt to a second region with minimal changes.
- If you’re not willing to modernize the app, you’re undercutting the whole value of cloud adoption.
🔁 This is a scalability issue disguised as an HA/DR objection.
Objections are natural—but they’re not a reason to settle for fragile systems. If anything, they’re an invitation to start a broader conversation. HA/DR isn’t a one-person decision, and it isn’t just a platform concern. It’s a shared responsibility—one that crosses teams, roles, and org charts.
🤝 Make HA/DR a Shared Responsibility
Don’t wait for someone else to own this. As a developer, you’re not just writing features—you’re building systems. And systems need to be resilient by design.
Your organization likely already has expectations around uptime, recovery time, and continuity. If your solution doesn’t meet them, you may find yourself back at the drawing board—after the fire drill.
- Start upstream. Partner with infrastructure and security teams early to understand the technical constraints.
- Go beyond user stories. Talk to business stakeholders about RTO/RPO goals and the true cost of downtime.
- If your team has no standards—create them. Recommend something. Personally, I like Active/Active with Hot/Hot for its clarity and resilience.
- Don’t skip the dry runs. Test failover scenarios before they become your next incident.
💡 HA/DR is too important to be someone else’s problem. Build it into how you think.
🧘 Architect for Peace of Mind
Don’t waste another minute away from the things that truly matter.
Yes, there are strong business cases for HA/DR—compliance, availability targets, reputational risk—but the most important reason is personal.
- Your company can’t tolerate downtime.
- It’s your responsibility to bring the system back up.
- You want to keep your job to provide for your family.
- So you stay online. You cancel the trip. You miss the recital—again.
That’s a responsible decision… in the short term. But over time, it’s a recipe for burnout. You don’t need to choose between reliability and your life.
With the right strategy—planned, tested, and embedded in your architecture—you can walk away when you need to. You can trust that the system will hold.
💡 Architecting for uptime is architecting for peace of mind.
You don’t need to build a perfect system—just one that fails gracefully, recovers fast, and lets you live your life.

✅ Key Takeaways
- Failure is inevitable—design for resilience, not perfection.
- Use Azure-native features like Front Door, Availability Zones, and paired regions to improve both HA and DR.
- Prefer Active/Active with Hot/Hot when possible—it provides the fastest recovery and the greatest peace of mind.
- Test your recovery process regularly. “It should work” ≠ “It will work.”
- HA/DR isn’t just a technical choice—it’s a quality of life investment.
📬 Want Help?
If you’re trying to make your system more resilient—or just want to stop losing sleep—I’d love to talk.